
Documentation has traditionally been maintained separately from but in parallel to software systems as they’ve been implemented and maintained. Keeping the documentation in sync with an evolving system is a well-known challenge.
Documentation itself comes in many forms and even if the external documents are not maintained with sufficient, shall we say… enthusiasm, there are many ways to mitigate the pain of understanding older code and data. They include, among others:
- solid naming conventions. Hungarian notation was one version of this that is now considered somewhat passé, but there are other aspects of naming things that still apply.
- comments embedded in code, especially if they include dates, names, and reasons
- comments added to source code control activities
- minutes of configuration management board meetings
- engineering notes
- partial documentation. For example, the description of configuration files might be updated when changes are made because the users need it, even if the formal documentation is never touched.
- e-mails
- automated analysis, diagramming, and documentation tools
- example data artifacts
It might be difficult to embed information about the code into the working system (beyond the idea that some languages are designed to be somewhat self-documenting) but any part of a system that is modular can certainly have its metadata embedded.
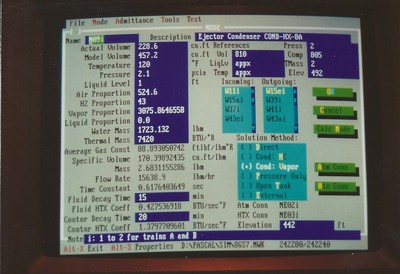
The screenshot below was from a tool I created to document and calculate the parameters and starting values for the thermo-hydraulic models I wrote for nuclear power plant simulators. The entries in the upper right corner are to record the document numbers where the supporting information came from. The plant I primarily modeled sent close to 10,000 copied documents to our office, each of which was assigned an index number. Additional documents created as letters, emails, memoranda, technical updates, and the like were added to the library over the course of the project.
I was thinking about this because of a recent project I worked on had to regularly incorporate data sets from many similar sources in several different formats. The organizer in charge of acquiring, formatting, and collating this information every year had to maintain the contact information for every co-worker who provided the information. If that person was replaced during the year the organizer had to figure out who the replacement was. Those responsible for providing the information didn’t always remember what had been provided previously, how it was done, or what it meant. The content, format, and labeling of the data might also have changed in the interim.
In theory the organizer could have gotten the providers to document all of those procedures and labels and forward that metadata along with the actual input data. It could then have been maintained in a fairly neat way, apart from how the inputs were folded into the final product. The metadata information could have been printed and placed in a notebook, organized into a single document, or saved in some other way. If this information were saved each year, along with the contact information of the providers, both the organizer and providers would have maintained a much better memory of how things should be done from year to year. As it was it was up to the organizer to do a lot of cajoling and hand-processing and recreating the crime every year to get the needed data.
I encountered this organizer when assigned to a project meant to calculate the number of staff needed to support the yearly volume of activities carried out at each of a large number of locations. The project’s purpose was to automate the system to standardize the incorporation of the input data, identify errors in the content and format of the data, perform the calculations in a more reliable and consistent way, and make the results available interactively to a wider range of people.
We therefore had the opportunity to define any data structure we wanted. It occurred to me that we could embed the metadata for all of the formal input artifacts and procedures into the data structure (and user interface) itself. We could also make the program keep track of which data inputs were updated and when, which at the very least could serve as an embedded to-do list that ensured everything got done.
Input data usually came in the form of individual spreadsheet pages which would then be folded into the target spreadsheet as new tabs. The data could also come as comma-separated variable (.CSV) files, as database files, or as raw text. As the automated system was expanded, it could have been connected directly to the live databases from which the contacts pulled the information they sent to the organizer.
The activity information received was usually formatted as tables. The columns usually described activities while the rows were usually associated with locations. At least one of the columns had to contain information about the location so the data could be collated on that basis. There were some exceptions, but let me describe what a good metadata description might have included for the standard case where the information came formatted as a standard table:
Contact Name: name
Contact Phone Number: phone
Contact E-mail: e-mail
Contact Office Location: office
Data Artifact Type: .CSV file, Excel File, etc.
Date Received: date
Time Received: time
System Data Retrieved From: system name
First Header Row: r1
Last Header Row: rn
First Column: c1
Last Column: cn
Column containing Location Code: col
Column 1 Header Line 1: header text 1
…
Column 1 Header Line n: header text n
Column 1 Meaning: description
Column 1 Units: units
…
…
Column n Header Line 1: header text 1
…
Column n Header Line n: header text n
Column n Meaning: description
Column n Units: units
Link to Example Artifact: file location and name (or web url)
Description of How Data Was Acquired: Provider’s account of how the data artifact was produced
Now we have a means of ensuring that the organizer asks for all of the artifacts needed. The organizer knows who in the organization to contact. The request for the information could be automated. It would be nothing to have the system embed this information in an e-mail saying, “Hey, I’m <so and so>, the organizer for <the whatever>, and here is the data you sent me last year, its meaning and its format, and how you produced the data the last time. Please send me the updated data by <whenever>, or contact me if there are any difficulties.”
If the implementers were really ambitious they could use the metadata information to test the content and format of the received artifacts automatically, particularly if the metadata definition incorporated information about what constituted valid values for each type of information. The information would also be available within the system’s UI, say, via a context menu that comes up when the user right-clicks on a relevant data item.
If the system were enhanced to automatically link to an external database to pull data directly, the metadata could be expanded to include the location and name of the relevant database, credentials needed to log into it, and the text of the query or queries needed to generate the desired data. Moreover, the automated process could be automatically run at intervals to ensure that the retrieved information is still accessible and valid. If the automatic access fails, the organizer and provider can be automatically notified so they can figure out what changed and make the necessary updates.
I noted above that any modular part of a system could have metadata associated with it, and this can include modular code. The system in question included modular scripts that performed calculations, and allowing the user to see and maintain both the scripts and the related meta-documentation would have gone a long way to ensure that the documentation was kept up as well as the “code”. There were also cases where different sources of data were used or different calculations were used for activities at one or more locations. Metadata could be stored about exceptions and overrides as well.
Information about who defined or modified each modular element can be included as well, along with the date and time of those events, rationale and descriptions, permissions from approving authorities, links to configuration management meeting minutes, and so on. This metadata could then be queried and filtered to augment similar records that may or may not be kept elsewhere.
The point is that there are a lot of ways to make a system easier to maintain. Some parts are difficult. If you change the underlying code then you should do the work of updating the documentation where needed. This requires diligence and good management. If you can build procedures to automate the documentation and configuration management of the modular parts of the system, then in this day and age, where the constraints are less on system resources like speed and memory than on time, expertise, and management of complexity, it’s almost criminal not to do so.